 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnyx: Cost-Efficient Disk-Oblivious ANN Search
Apr 22, 2026Approximate nearest neighbor (ANN) search in AI systems increasingly handles sensitive data on third-party infrastructure. Trusted execution environments (TEEs) offer protection, but cost-efficient deployments must rely on external SSDs, which leaks user queries through disk access patterns to the host. Oblivious RAM (ORAM) can hide these access patterns but at a high cost; when paired with existing disk-based ANN search techniques, it makes poor use of SSD resources, yielding high latency and poor cost-efficiency. The core challenge for efficient oblivious ANN search over SSDs is balancing both bandwidth and access count. The state-of-the-art ORAM-ANN design minimizes access count at the ANN level and bandwidth at the ORAM level, each trading-off the other, leaving the combined system with both resources overutilized. We propose inverting this design, minimizing bandwidth consumption in the ANN layer and access count in the ORAM layer, since each component is better suited for its new role: ANN's inherent approximation allows for more bandwidth efficiency, while ORAM has no fundamental lower bounds on access count (as opposed to bandwidth). To this end, we propose a cost-efficient approach, Onyx, with two new co-designed components: Onyx-ANNS introduces a compact intermediate representation that proactively prunes the majority of bandwidth-intensive accesses without hurting recall, and Onyx-ORAM proposes a locality-aware shallow tree design that reduces access count while remaining compatible with bandwidth-efficient ORAM techniques. Compared to the state-of-the-art oblivious ANN search system, Onyx achieves $1.7-9.9\times$ lower cost and $2.3-12.3\times$ lower latency.
Privatar: Scalable Privacy-preserving Multi-user VR via Secure Offloading
Apr 19, 2026Multi-user virtual reality enables immersive interaction. However, rendering avatars for numerous participants on each headset incurs prohibitive computational overhead, limiting scalability. We introduce a framework, Privatar, to offload avatar reconstruction from headset to untrusted devices within the same local network while safeguarding attacks against adversaries capable of intercepting offloaded data. Privatar's key insight is that domain-specific knowledge of avatar reconstruction enables provably private offloading at minimal cost. (1) System level. We observe avatar reconstruction is frequency-domain decomposable via BDCT with negligible quality drop, and propose Horizontal Partitioning (HP) to keep high-energy frequency components on-device and offloads only low-energy components. HP offloads local computation while reducing information leakage to low-energy subsets only. (2) Privacy level. For individually offloaded, multi-dimensional signals without aggregation, worst-case local Differential Privacy requires prohibitive noise, ruining utility. We observe users' expression statistical distribution are slowly changing over time and trackable online, and hence propose Distribution-Aware Minimal Perturbation. DAMP minimizes noise based on each user's expression distribution to significantly reduce its effects on utility, retaining formal privacy guarantee. Combined, HP provides empirical privacy against expression identification attacks. DAMP further augments it to offer a formal guarantee against arbitrary adversaries. On a Meta Quest Pro, Privatar supports 2.37x more concurrent users at 6.5% higher reconstruction loss and 9% energy overhead, providing a better throughout-loss Pareto frontier over quantization, sparsity and local construction baselines. Privatar provides both provable privacy guarantee and stays robust against both empirical and NN-based attacks.
Architecting Secure AI Agents: Perspectives on System-Level Defenses Against Indirect Prompt Injection Attacks
Mar 31, 2026AI agents, predominantly powered by large language models (LLMs), are vulnerable to indirect prompt injection, in which malicious instructions embedded in untrusted data can trigger dangerous agent actions. This position paper discusses our vision for system-level defenses against indirect prompt injection attacks. We articulate three positions: (1) dynamic replanning and security policy updates are often necessary for dynamic tasks and realistic environments; (2) certain context-dependent security decisions would still require LLMs (or other learned models), but should only be made within system designs that strictly constrain what the model can observe and decide; (3) in inherently ambiguous cases, personalization and human interaction should be treated as core design considerations. In addition to our main positions, we discuss limitations of existing benchmarks that can create a false sense of utility and security. We also highlight the value of system-level defenses, which serve as the skeleton of agentic systems by structuring and controlling agent behaviors, integrating rule-based and model-based security checks, and enabling more targeted research on model robustness and human interaction.
SideQuest: Model-Driven KV Cache Management for Long-Horizon Agentic Reasoning
Feb 26, 2026Long-running agentic tasks, such as deep research, require multi-hop reasoning over information distributed across multiple webpages and documents. In such tasks, the LLM context is dominated by tokens from external retrieval, causing memory usage to grow rapidly and limiting decode performance. While several KV cache compression techniques exist for long-context inputs, we find that existing heuristics fail to support multi-step reasoning models effectively. We address this challenge with SideQuest -- a novel approach that leverages the Large Reasoning Model (LRM) itself to perform KV cache compression by reasoning about the usefulness of tokens in its context. To prevent the tokens associated with this management process from polluting the model's memory, we frame KV cache compression as an auxiliary task executed in parallel to the main reasoning task. Our evaluations, using a model trained with just 215 samples, show that SideQuest reduces peak token usage by up to 65% on agentic tasks with minimal degradation in accuracy, outperforming heuristic-based KV cache compression techniques.
Privasis: Synthesizing the Largest "Public" Private Dataset from Scratch
Feb 03, 2026Research involving privacy-sensitive data has always been constrained by data scarcity, standing in sharp contrast to other areas that have benefited from data scaling. This challenge is becoming increasingly urgent as modern AI agents--such as OpenClaw and Gemini Agent--are granted persistent access to highly sensitive personal information. To tackle this longstanding bottleneck and the rising risks, we present Privasis (i.e., privacy oasis), the first million-scale fully synthetic dataset entirely built from scratch--an expansive reservoir of texts with rich and diverse private information--designed to broaden and accelerate research in areas where processing sensitive social data is inevitable. Compared to existing datasets, Privasis, comprising 1.4 million records, offers orders-of-magnitude larger scale with quality, and far greater diversity across various document types, including medical history, legal documents, financial records, calendars, and text messages with a total of 55.1 million annotated attributes such as ethnicity, date of birth, workplace, etc. We leverage Privasis to construct a parallel corpus for text sanitization with our pipeline that decomposes texts and applies targeted sanitization. Our compact sanitization models (<=4B) trained on this dataset outperform state-of-the-art large language models, such as GPT-5 and Qwen-3 235B. We plan to release data, models, and code to accelerate future research on privacy-sensitive domains and agents.
ReasoningBomb: A Stealthy Denial-of-Service Attack by Inducing Pathologically Long Reasoning in Large Reasoning Models
Jan 29, 2026Large reasoning models (LRMs) extend large language models with explicit multi-step reasoning traces, but this capability introduces a new class of prompt-induced inference-time denial-of-service (PI-DoS) attacks that exploit the high computational cost of reasoning. We first formalize inference cost for LRMs and define PI-DoS, then prove that any practical PI-DoS attack should satisfy three properties: (1) a high amplification ratio, where each query induces a disproportionately long reasoning trace relative to its own length; (ii) stealthiness, in which prompts and responses remain on the natural language manifold and evade distribution shift detectors; and (iii) optimizability, in which the attack supports efficient optimization without being slowed by its own success. Under this framework, we present ReasoningBomb, a reinforcement-learning-based PI-DoS framework that is guided by a constant-time surrogate reward and trains a large reasoning-model attacker to generate short natural prompts that drive victim LRMs into pathologically long and often effectively non-terminating reasoning. Across seven open-source models (including LLMs and LRMs) and three commercial LRMs, ReasoningBomb induces 18,759 completion tokens on average and 19,263 reasoning tokens on average across reasoning models. It outperforms the the runner-up baseline by 35% in completion tokens and 38% in reasoning tokens, while inducing 6-7x more tokens than benign queries and achieving 286.7x input-to-output amplification ratio averaged across all samples. Additionally, our method achieves 99.8% bypass rate on input-based detection, 98.7% on output-based detection, and 98.4% against strict dual-stage joint detection.
ReasAlign: Reasoning Enhanced Safety Alignment against Prompt Injection Attack
Jan 15, 2026Large Language Models (LLMs) have enabled the development of powerful agentic systems capable of automating complex workflows across various fields. However, these systems are highly vulnerable to indirect prompt injection attacks, where malicious instructions embedded in external data can hijack agent behavior. In this work, we present ReasAlign, a model-level solution to improve safety alignment against indirect prompt injection attacks. The core idea of ReasAlign is to incorporate structured reasoning steps to analyze user queries, detect conflicting instructions, and preserve the continuity of the user's intended tasks to defend against indirect injection attacks. To further ensure reasoning logic and accuracy, we introduce a test-time scaling mechanism with a preference-optimized judge model that scores reasoning steps and selects the best trajectory. Comprehensive evaluations across various benchmarks show that ReasAlign maintains utility comparable to an undefended model while consistently outperforming Meta SecAlign, the strongest prior guardrail. On the representative open-ended CyberSecEval2 benchmark, which includes multiple prompt-injected tasks, ReasAlign achieves 94.6% utility and only 3.6% ASR, far surpassing the state-of-the-art defensive model of Meta SecAlign (56.4% utility and 74.4% ASR). These results demonstrate that ReasAlign achieves the best trade-off between security and utility, establishing a robust and practical defense against prompt injection attacks in real-world agentic systems. Our code and experimental results could be found at https://github.com/leolee99/ReasAlign.
Machine Learning with Privacy for Protected Attributes
Jun 24, 2025



Differential privacy (DP) has become the standard for private data analysis. Certain machine learning applications only require privacy protection for specific protected attributes. Using naive variants of differential privacy in such use cases can result in unnecessary degradation of utility. In this work, we refine the definition of DP to create a more general and flexible framework that we call feature differential privacy (FDP). Our definition is simulation-based and allows for both addition/removal and replacement variants of privacy, and can handle arbitrary and adaptive separation of protected and non-protected features. We prove the properties of FDP, such as adaptive composition, and demonstrate its implications for limiting attribute inference attacks. We also propose a modification of the standard DP-SGD algorithm that satisfies FDP while leveraging desirable properties such as amplification via sub-sampling. We apply our framework to various machine learning tasks and show that it can significantly improve the utility of DP-trained models when public features are available. For example, we train diffusion models on the AFHQ dataset of animal faces and observe a drastic improvement in FID compared to DP, from 286.7 to 101.9 at $\epsilon=8$, assuming that the blurred version of a training image is available as a public feature. Overall, our work provides a new approach to private data analysis that can help reduce the utility cost of DP while still providing strong privacy guarantees.
How much do language models memorize?
May 30, 2025We propose a new method for estimating how much a model ``knows'' about a datapoint and use it to measure the capacity of modern language models. Prior studies of language model memorization have struggled to disentangle memorization from generalization. We formally separate memorization into two components: \textit{unintended memorization}, the information a model contains about a specific dataset, and \textit{generalization}, the information a model contains about the true data-generation process. When we completely eliminate generalization, we can compute the total memorization, which provides an estimate of model capacity: our measurements estimate that GPT-style models have a capacity of approximately 3.6 bits per parameter. We train language models on datasets of increasing size and observe that models memorize until their capacity fills, at which point ``grokking'' begins, and unintended memorization decreases as models begin to generalize. We train hundreds of transformer language models ranging from $500K$ to $1.5B$ parameters and produce a series of scaling laws relating model capacity and data size to membership inference.
Stronger Enforcement of Instruction Hierarchy via Augmented Intermediate Representations
May 25, 2025
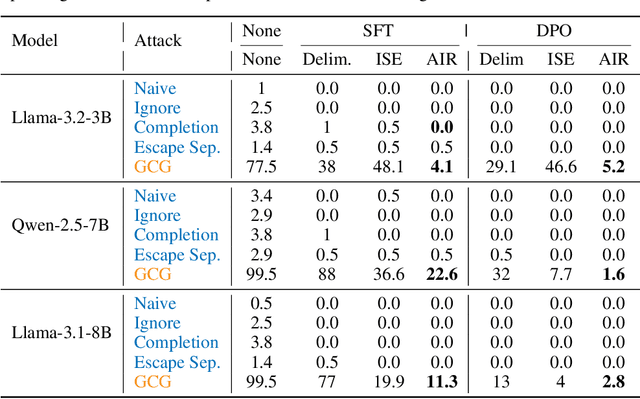
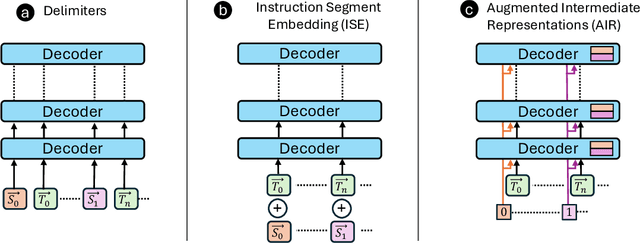
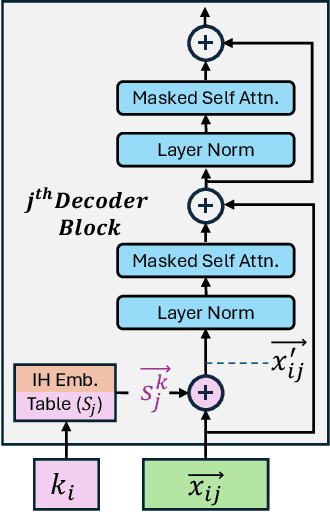
Prompt injection attacks are a critical security vulnerability in large language models (LLMs), allowing attackers to hijack model behavior by injecting malicious instructions within the input context. Recent defense mechanisms have leveraged an Instruction Hierarchy (IH) Signal, often implemented through special delimiter tokens or additive embeddings to denote the privilege level of input tokens. However, these prior works typically inject the IH signal exclusively at the initial input layer, which we hypothesize limits its ability to effectively distinguish the privilege levels of tokens as it propagates through the different layers of the model. To overcome this limitation, we introduce a novel approach that injects the IH signal into the intermediate token representations within the network. Our method augments these representations with layer-specific trainable embeddings that encode the privilege information. Our evaluations across multiple models and training methods reveal that our proposal yields between $1.6\times$ and $9.2\times$ reduction in attack success rate on gradient-based prompt injection attacks compared to state-of-the-art methods, without significantly degrading the model's utility.